
深度求索新出的MoE大模型V2,這價格低得讓我懷疑人生
這年月,AI公司們都在拼誰更會省銀子,深度求索直接亮出一張王牌:V2模型性能跟GPT-4有得一拼,可價格卻只要它的百分之一。這操作,簡直就像在菜市場砍價,老板一激動,直接給你來了個骨折優惠。

性能強到離譜
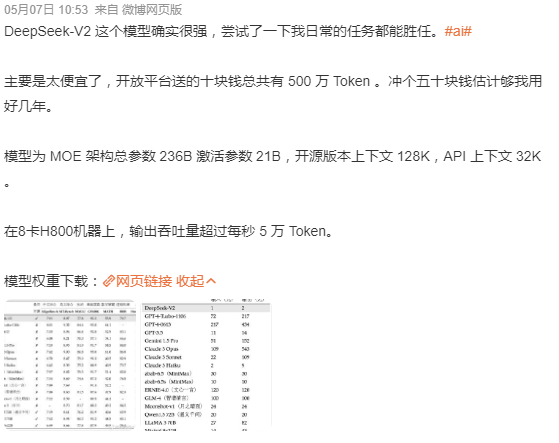
V2那家伙參數高達2360億,結果活躍的才210億,這就像學霸考試時只使出了三成功力就秒殺了所有人。中文能力那叫一個杠杠的,直接跟GPT-4-Turbo和文心4.0一較高下AI模型,至于英文,那更是吊打當前最火的開源模型。
練了8.1萬億個token,結果算力才Llama 3 70B的五分之一。這就像你花五毛錢搞了個好萊塢大片級別的特效,讓隔壁Meta那幫人看了都得趕緊改PPT,連夜加班。
價格低到谷底
V2的API收費版只要GPT-4的百分之一那么貴開源大模型新秀DeepSeek-V2發布,媲美GPT-4且價格僅百分之一,而且還能白嫖五百個token。這定價,搞不好其他公司的銷售團隊都開始琢磨改行賣紅薯去了。
有網友一算,一臺服務器每小時能賺個七成,這東西根本不是什么AI公司,簡直就是個活脫脫的印鈔機附體。深度求索這幫家伙,估計是想用低價策略直接把競爭對手干趴下,畢竟在科技圈里,“薄利多銷”這招還是挺管用的。

技術騷操作一堆
為了省點小錢,V2這小子搞了個低秩鍵值壓縮技術,給數據來了個減肥大法。MoE架構這東西也來個新把戲,16路并行訓練搞出多線程的感覺,通信成本還低得跟啥似的。
這東西簡直逆天,居然能跟OpenAI的API無縫對接,用戶連代碼都省得動一根指頭。這操作就像你去麥當勞點了個漢堡,服務員直接給你端來一整份肯德基全家桶,還笑嘻嘻地說:“湊合吃,反正都一個味兒。”
開源界的攪局者
現在這開源模型圈兒,簡直跟手機圈兒那小米年代似的:性能跟頂級旗艦杠上,價格直接殺到最低點。V2那中文資料庫,比Llama 3豐富多了,質量也是杠杠的AI模型,簡直給老外開了個中文速成班。
這AI圈的內卷速度,簡直比網紅過氣還猛。今天個V2風光無限,明兒個說不定就被哪個車庫里的創業小公司給超越了。畢竟在這行,最厲害的模型永遠是那個“下一款”。
商業邏輯被顛覆
老式的靠高價API撈金的玩法,現在讓V2給整了個大翻車。毛利率高達70%開源大模型新秀DeepSeek-V2發布,媲美GPT-4且價格僅百分之一,這數據說明技術降價比漲價更能讓用戶掏腰包。其他廠商要么學學降價,要么就只能拿“我們更安全”這種玄乎其玄的賣點來唬人。

這深度探索的招數,跟用拼多多那套玩法打高端局似的。以后要是投資大佬問“你們這跟GPT-4有啥不一樣”,創業小能手們估計都得齊聲答:“咱們這更實惠。”
這事挺棘手的:咱們公司要是打算搞個大模型API,是得選那個性能超群、價格卻讓人心疼的GPT-4,還是選那個價格親民、量又足的V2?這倆家伙,一個貴得要死,一個便宜得要命,真是讓人頭大。



