
AI模型訓(xùn)練中的“變速器”:學(xué)習(xí)率調(diào)整的藝術(shù)
在AI模型訓(xùn)練這條賽道上,學(xué)習(xí)率就像是汽車的變速器,調(diào)得好,能讓模型跑得又快又穩(wěn);調(diào)得不好,可能就卡在半路,甚至翻車,今天咱們就來聊聊這個AI訓(xùn)練里的關(guān)鍵參數(shù)——學(xué)習(xí)率調(diào)整,看看它是怎么影響模型性能的,又該怎么調(diào)才合適。
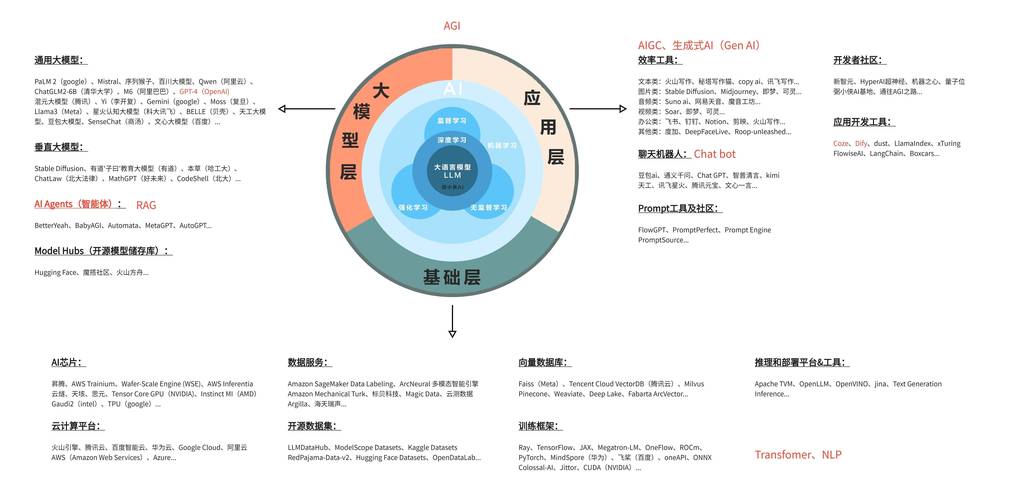
學(xué)習(xí)率,就是模型在每次迭代中更新參數(shù)的步長,步子邁大了,可能就跨過了最優(yōu)解;步子邁小了,又得走好久才能到,找到一個合適的學(xué)習(xí)率,對模型訓(xùn)練來說至關(guān)重要。
剛開始訓(xùn)練的時候,模型對數(shù)據(jù)的了解還不多,這時候?qū)W習(xí)率可以設(shè)得大一些,讓模型快速探索參數(shù)空間,找到大致的方向,就像開車剛起步,油門可以踩得深一點,但隨著訓(xùn)練的深入,模型對數(shù)據(jù)的理解越來越深,這時候就得把學(xué)習(xí)率調(diào)小,讓模型在最優(yōu)解附近精細(xì)調(diào)整,避免因為步子太大而錯過。
舉個例子,假設(shè)我們在訓(xùn)練一個圖像分類模型,一開始,學(xué)習(xí)率設(shè)為0.1,模型能快速收斂到一個不錯的解,但到了后期,如果還保持這個學(xué)習(xí)率,模型可能會在最優(yōu)解附近來回震蕩,就是找不到那個最精確的點,這時候,我們就得把學(xué)習(xí)率降下來,比如降到0.01,讓模型慢慢逼近最優(yōu)解。
學(xué)習(xí)率調(diào)整也不是一成不變的,現(xiàn)在有很多自適應(yīng)的學(xué)習(xí)率調(diào)整策略,比如Adam、RMSprop等,它們能根據(jù)模型訓(xùn)練的情況自動調(diào)整學(xué)習(xí)率,讓訓(xùn)練過程更加高效,但即便如此,了解學(xué)習(xí)率調(diào)整的基本原理,還是能幫助我們更好地理解模型訓(xùn)練的過程,遇到問題時也能更快地找到原因。
學(xué)習(xí)率調(diào)整就像是AI模型訓(xùn)練中的一門藝術(shù),需要我們在實踐中不斷摸索和調(diào)整,才能讓模型在訓(xùn)練的道路上跑得又快又穩(wěn),達(dá)到我們期望的性能。

高效落地實踐?")
高效落地實踐?")
用技巧?")
用說明?")
友昵稱:快手推廣助手")