
AI模型在線更新:技術演進、挑戰與未來展望
在當今這個數據驅動的時代,人工智能(AI)技術正以前所未有的速度改變著我們的生活和工作方式,從智能家居到自動駕駛,從醫療診斷到金融風控,AI模型的應用無處不在,極大地提升了效率與準確性,隨著數據量的爆炸性增長和應用場景的日益復雜,如何高效、安全地實現AI模型的在線更新,成為了業界關注的焦點,本文將深入探討AI模型在線更新的技術演進、面臨的挑戰以及未來的發展趨勢。
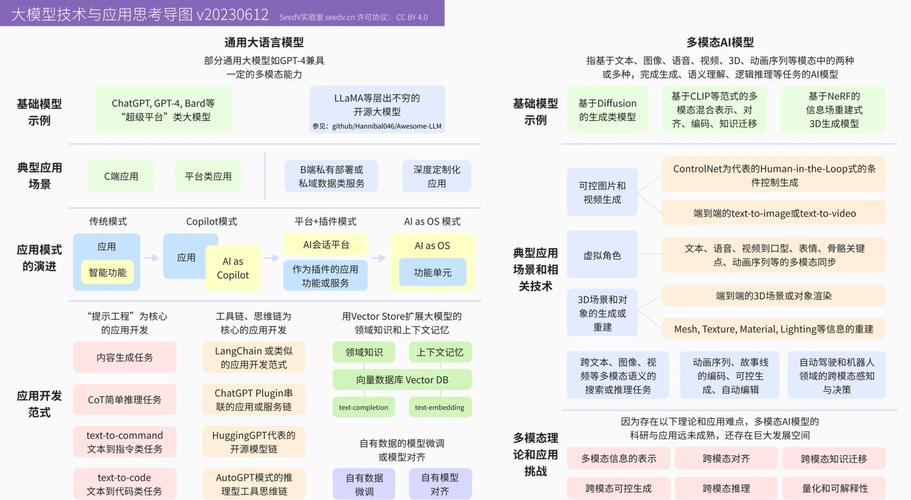
AI模型在線更新的技術演進
傳統更新方式的局限性
早期,AI模型的更新往往依賴于離線訓練,即收集大量數據后,在高性能計算集群上進行長時間的訓練,然后將訓練好的模型部署到生產環境中,這種方式雖然穩定,但存在明顯的局限性:一是更新周期長,難以快速響應市場變化;二是資源消耗大,每次更新都需要重新訓練整個模型,成本高昂;三是靈活性差,無法根據實時數據動態調整模型參數。
在線學習與增量學習的興起
為了克服傳統更新方式的不足,在線學習(Online Learning)和增量學習(Incremental Learning)技術應運而生,在線學習允許模型在接收新數據的同時進行實時更新,無需重新訓練整個模型,大大縮短了更新周期,增量學習則進一步優化了這一過程,它能夠在保留舊知識的基礎上,逐步學習新知識,實現模型的平滑過渡,這兩種技術的結合,使得AI模型能夠更加靈活地適應環境變化,提高模型的適應性和泛化能力。
聯邦學習與邊緣計算的融合
隨著物聯網(IoT)和5G技術的發展,數據產生和處理的邊界日益模糊,聯邦學習(Federated Learning)作為一種分布式機器學習框架,允許在保護數據隱私的前提下,利用多個設備或節點的本地數據進行模型訓練,然后將訓練結果匯總到中心服務器進行模型更新,這種方式不僅提高了數據利用率,還增強了模型的安全性和隱私保護能力,邊緣計算的興起,使得模型更新可以在靠近數據源的地方進行,進一步降低了延遲,提高了響應速度。
AI模型在線更新面臨的挑戰
數據質量與多樣性
在線更新依賴于持續的數據流,數據的質量和多樣性直接影響模型的性能,如何確保收集到的數據準確無誤、具有代表性,同時避免數據偏見,是AI模型在線更新面臨的首要挑戰。
模型穩定性與安全性
頻繁的在線更新可能導致模型性能波動,甚至出現災難性遺忘(Catastrophic Forgetting)現象,即模型在學習新知識時忘記了舊知識,模型更新過程中還可能遭受攻擊,如數據投毒、模型竊取等,威脅模型的安全性。
計算資源與能耗
在線更新需要持續的計算資源支持,尤其是在處理大規模數據時,對硬件性能和能耗提出了更高要求,如何在保證更新效率的同時,降低能耗,實現綠色計算,是亟待解決的問題。
自動化與智能化更新
AI模型的在線更新將更加自動化和智能化,通過引入強化學習、元學習等技術,模型能夠根據自身性能和環境變化,自動調整學習策略,實現自我優化。
跨領域融合與創新
AI模型在線更新將與區塊鏈、量子計算等前沿技術深度融合,探索新的應用場景和商業模式,利用區塊鏈技術確保數據來源的可信性和模型更新的透明性,利用量子計算加速模型訓練過程,提升更新效率。
倫理與法規的完善
隨著AI技術的廣泛應用,倫理和法規問題日益凸顯,需要建立健全的AI倫理框架和法律法規,確保AI模型在線更新的合法合規,保護用戶隱私和數據安全。
AI模型在線更新是AI技術發展的必然趨勢,它不僅關乎技術的進步,更關乎社會的福祉,面對挑戰,我們應積極尋求解決方案,推動AI技術的健康、可持續發展,為人類社會創造更多價值。




還沒有評論,來說兩句吧...