想深入了解AI模型穩定性表現嗎?這篇專業產品評測聚焦于此,為你全方位剖析相關產品,帶你清晰知曉其優劣,是了解AI模型穩定性產品的不二之選!
AI模型穩定性:從理論到實踐,如何讓智能更可靠?
嘿,朋友們,今天咱們來聊聊一個既高大上又接地氣的話題——AI模型穩定性,在這個AI滿天飛的時代,從智能家居到自動駕駛,從醫療診斷到金融風控,AI模型無處不在,它們就像是我們生活中的隱形助手,讓一切變得更加便捷高效,但你有沒有想過,這些看似無所不能的AI模型,其實也有它們的“小脾氣”,那就是穩定性問題。
想象一下,你正用著一款智能語音助手,突然有一天它開始“胡言亂語”,或者你的自動駕駛汽車在關鍵時刻“猶豫不決”,那得多讓人頭疼啊!這就是AI模型穩定性不足可能帶來的后果,今天咱們就來深入探討一下,如何讓AI模型更加穩定可靠,成為我們真正信賴的伙伴。
咱們得明白,AI模型為啥會不穩定?這背后的原因多種多樣,數據質量是關鍵,AI模型就像是個學生,它學得好不好,很大程度上取決于老師(也就是數據)教得怎么樣,如果數據里有錯誤、偏差或者不完整,那模型學出來的“知識”自然也就靠不住了,一個用于識別貓狗的AI模型,如果訓練數據里大部分都是貓的照片,那它遇到狗的時候可能就會“犯迷糊”。
模型結構的設計也很重要,就像蓋房子,地基不穩,房子就容易倒,AI模型的結構如果設計得不合理,比如層數太多、參數設置不當,就容易導致過擬合或者欠擬合,影響模型的泛化能力,過擬合就是模型在訓練數據上表現很好,但在新數據上卻一塌糊涂;欠擬合則是模型連訓練數據都學不好,更別提應對新情況了。
怎么解決這些問題,提高AI模型的穩定性呢?這里有幾個小妙招,咱們一一來看。
第一招,數據預處理,在訓練模型之前,對數據進行清洗、標注、增強等操作,確保數據的質量和多樣性,對于圖像數據,可以進行旋轉、縮放、裁剪等變換,增加數據的豐富度;對于文本數據,可以進行分詞、去停用詞、詞性標注等處理,提高數據的可用性,這樣,模型就能學到更全面、更準確的知識。
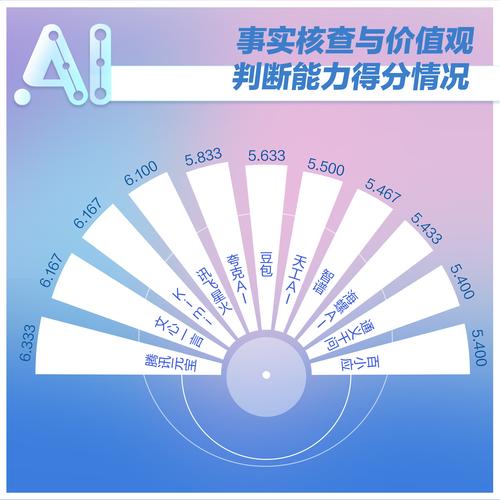
第二招,模型優化,選擇合適的模型結構,調整參數設置,避免過擬合和欠擬合,可以使用正則化技術來限制模型的復雜度,防止過擬合;也可以使用交叉驗證來評估模型的性能,選擇最優的參數組合,還可以嘗試使用集成學習的方法,將多個模型的預測結果結合起來,提高整體的穩定性和準確性。
第三招,持續監控與迭代,AI模型不是一次性的產品,而是需要不斷學習和進化的,在模型上線后,要持續監控其性能表現,及時發現并解決問題,可以設置一些性能指標,如準確率、召回率、F1值等,定期評估模型的性能;也可以收集用戶的反饋,了解模型在實際應用中的表現,一旦發現問題,就要及時調整模型或者數據,進行迭代優化。
舉個例子吧,某電商公司使用AI模型來預測用戶的購買行為,以便進行精準營銷,一開始,模型的穩定性并不理想,預測結果時好時壞,后來,他們通過數據預處理,去除了大量噪聲數據,增加了用戶行為數據的多樣性;對模型結構進行了優化,采用了更先進的深度學習算法,經過一段時間的迭代和優化,模型的穩定性得到了顯著提升,預測準確率也大幅提高,為公司帶來了可觀的收益。
朋友們,AI模型穩定性并不是一個遙不可及的目標,只要我們從數據質量、模型結構、持續監控等方面入手,不斷優化和迭代,就能讓AI模型變得更加穩定可靠,在這個AI時代,讓我們一起努力,讓智能更加貼心、更加值得信賴吧!