專注AI模型測試領域,我們提供全方位配件支持!優質配件精準適配,助力測試高效開展,為AI模型性能提升保駕護航,是您AI測試路上的可靠伙伴!
AI模型測試那些事兒:從理論到實戰的全面解析
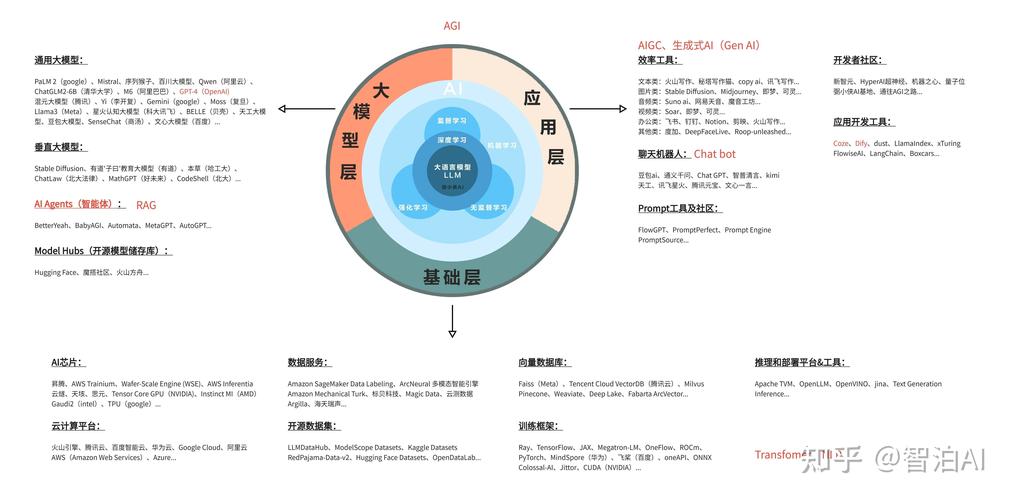
嘿,朋友們,今天咱們來聊聊一個既高大上又接地氣的話題——AI模型測試,在這個AI技術滿天飛的時代,無論是智能語音助手、自動駕駛汽車,還是推薦系統,背后都離不開AI模型的默默支撐,但你知道嗎?這些看似無所不能的AI模型,在正式上崗前,都得經過一番嚴格的“體檢”,也就是咱們今天要說的AI模型測試。

想象一下,你開發了一個AI模型,它能根據用戶的購物歷史推薦商品,聽起來挺酷的,對吧?但如果這個模型總是推薦一些用戶根本不感興趣的東西,那用戶很快就會失去耐心,轉而投向競爭對手的懷抱,AI模型測試的重要性不言而喻,它就像是AI產品的“質量檢測員”,確保模型在實際應用中能夠穩定、準確地工作。
AI模型測試到底測些什么呢?就是兩大塊:性能測試和準確性測試。
性能測試,就像是給AI模型做一次“體能測試”,你得看看它在不同負載下的表現如何,比如同時處理多少個請求時還能保持響應速度,內存占用會不會過高,CPU使用率會不會飆升等,這就像是你買了一輛新車,得試試它在高速上能不能穩穩地跑,油耗高不高,剎車靈不靈,舉個例子,有個團隊開發了一個圖像識別模型,在實驗室環境下表現良好,但一到實際應用中,面對大量并發請求就頻繁崩潰,后來經過性能測試,發現是模型在處理大數據量時內存管理不當,優化后問題迎刃而解。
準確性測試,則是檢驗AI模型的“智商”是否達標,你得用各種數據去“考”它,看看它能不能正確識別、分類或預測,這就像是你參加一場考試,得看看你能答對多少題,得分高不高,一個用于醫療診斷的AI模型,你得用大量的病例數據去測試它,看看它能不能準確判斷病情,給出合理的治療建議,有個真實的案例,一個AI醫療診斷模型在初步測試中表現不錯,但在實際應用中,對于某些罕見病的診斷準確率卻很低,經過深入分析,發現是訓練數據中罕見病的樣本太少,導致模型“見識”不夠廣,后來增加了相關樣本,模型的準確性大幅提升。
除了這兩大塊,AI模型測試還得考慮一些特殊情況,比如模型的魯棒性(也就是抗干擾能力)、可解釋性(模型為什么這么決策)等,魯棒性測試就像是給AI模型來一場“極限挑戰”,看看它在面對噪聲數據、異常輸入時能不能保持穩定,可解釋性測試則是為了讓人們更信任AI模型,畢竟,誰也不想用一個“黑箱”來做決策。
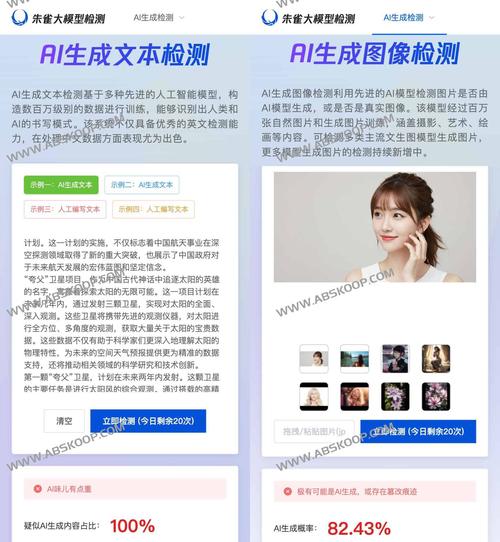
在實際操作中,AI模型測試可不是一件輕松的事,你得準備大量的測試數據,設計各種測試場景,還得不斷迭代優化測試方案,為了找到一個模型的“bug”,你可能得反復測試上百次,甚至上千次,但正是這種嚴謹的態度,才能確保AI模型在實際應用中能夠發揮出最大的價值。
AI模型測試是AI產品開發過程中不可或缺的一環,它就像是AI產品的“守護神”,確保模型在正式上崗前能夠經過嚴格的考驗,為用戶提供穩定、準確的服務,如果你正在從事AI相關工作,或者對AI技術感興趣,不妨多了解一下AI模型測試,說不定你會發現一個全新的世界呢!