
AI模型特征提取:原理、方法與應用深度剖析
在人工智能(AI)的快速發展浪潮中,特征提取作為連接原始數據與高級智能分析的關鍵橋梁,扮演著至關重要的角色,無論是圖像識別、自然語言處理,還是語音識別、推薦系統,AI模型都需要從海量、復雜的數據中提取出有意義的特征,以便進行后續的學習、推理和決策,本文將深入探討AI模型特征提取的原理、主流方法及其在不同領域的應用,旨在為讀者提供一個全面而深入的理解框架。
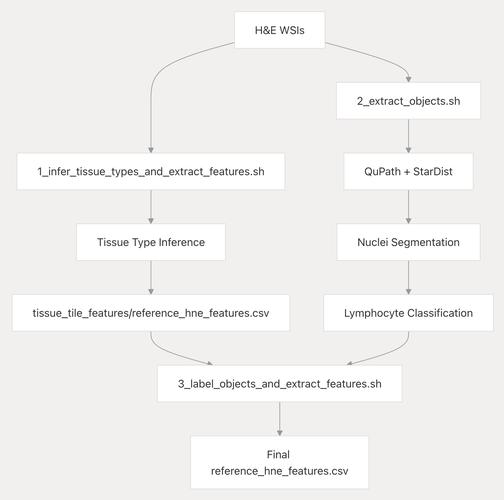
特征提取的基本原理
特征提取,簡而言之,是從原始數據中自動或半自動地識別并提取出對后續任務有用的信息的過程,這一過程的核心在于將高維、復雜的數據空間映射到低維、更具代表性的特征空間,從而簡化問題,提高模型的效率和準確性,特征提取的有效性直接關系到AI模型的性能,是機器學習、深度學習等領域研究的重要方向。
特征提取的主要方法
- 手工特征工程
在深度學習興起之前,手工特征工程是特征提取的主要手段,研究者根據領域知識,設計一系列算法來提取數據的特定屬性,如圖像處理中的邊緣檢測、紋理分析,自然語言處理中的詞袋模型、TF-IDF等,這些方法雖然需要大量的人工干預和專業知識,但在特定任務上往往能取得不錯的效果。
- 深度學習自動特征提取
隨著深度學習技術的興起,自動特征提取成為可能,卷積神經網絡(CNN)、循環神經網絡(RNN)及其變體(如LSTM、GRU)等深度學習模型,通過多層非線性變換,能夠自動從數據中學習到層次化的特征表示,在圖像識別中,CNN通過卷積層、池化層等結構,逐步提取出從邊緣、紋理到物體部件、整體的高層次特征,極大地提高了特征提取的效率和準確性。
- 無監督與自監督學習特征提取
無監督學習,如聚類、降維(PCA、t-SNE)等,通過挖掘數據內部的統計規律,實現特征的自動提取,而自監督學習則是一種更高級的形式,它通過設計特定的預訓練任務(如掩碼語言模型、對比學習),讓模型在沒有明確標簽的情況下學習到數據的內在結構,從而提取出有用的特征,這些方法在數據標注成本高昂或難以獲取的場景下尤為重要。
特征提取在不同領域的應用
- 計算機視覺
在計算機視覺領域,特征提取是圖像識別、目標檢測、圖像分割等任務的基礎,CNN通過其強大的特征學習能力,在ImageNet等大規模圖像分類競賽中取得了巨大成功,隨著注意力機制、Transformer等技術的引入,特征提取的能力進一步提升,推動了計算機視覺技術的快速發展。
- 自然語言處理
在自然語言處理中,特征提取同樣至關重要,從早期的詞袋模型到現代的詞嵌入(如Word2Vec、GloVe)、上下文嵌入(如BERT、GPT系列),特征提取技術不斷進步,使得機器能夠更好地理解人類語言,實現情感分析、機器翻譯、問答系統等復雜任務。
- 語音識別與合成
語音識別與合成領域也離不開特征提取,MFCC(梅爾頻率倒譜系數)等傳統特征提取方法,結合深度學習模型,顯著提高了語音識別的準確率和魯棒性,在語音合成中,通過提取語音的韻律、音色等特征,可以實現更加自然、流暢的語音輸出。
- 推薦系統
在推薦系統中,特征提取用于捕捉用戶行為、物品屬性等多源信息,構建用戶-物品交互矩陣,進而實現個性化推薦,深度學習模型,如深度神經網絡(DNN)、深度興趣網絡(DIN)等,通過自動學習用戶和物品的高層次特征表示,有效提升了推薦的準確性和多樣性。
挑戰與未來趨勢
盡管特征提取技術取得了顯著進展,但仍面臨諸多挑戰,如何處理高維稀疏數據、如何平衡特征提取的效率與準確性、如何解釋深度學習模型提取的特征等,隨著技術的不斷進步,特征提取將更加注重跨模態融合、可解釋性增強以及隱私保護等方面的發展。
- 跨模態融合:隨著多媒體數據的爆炸式增長,如何有效融合來自不同模態(如文本、圖像、音頻)的信息,提取出更加全面、豐富的特征,成為新的研究熱點。
- 可解釋性增強:深度學習模型的黑箱特性限制了其在某些關鍵領域的應用,特征提取技術將更加注重可解釋性,通過可視化、注意力機制等手段,揭示模型決策背后的邏輯。
- 隱私保護:在數據隱私日益受到重視的今天,如何在保護用戶隱私的前提下進行有效的特征提取,成為亟待解決的問題,聯邦學習、差分隱私等技術為此提供了可能的解決方案。
特征提取作為AI模型的核心環節,其重要性不言而喻,從手工特征工程到深度學習自動特征提取,再到無監督與自監督學習的興起,特征提取技術不斷演進,為AI的發展注入了強大動力,面對未來的挑戰與機遇,我們有理由相信,隨著技術的不斷進步和創新,特征提取將在更多領域發揮重要作用,推動AI技術向更高水平邁進。




還沒有評論,來說兩句吧...